Les k plus proches voisins
Algorithmique
Plan
Machine learning et histoire
L'idée d'apprentissage automatique (machine learning) est réellement née en 1936 avec le concept de machine universelle d'Alan Turing et de son article de 1950 sur le test de turing. En 1943 deux chercheurs représentent le fonctionnement des neurones avec des circuits électriques, c'est le début de la théorie sur les réseaux neuronaux. En 1952 Arthur Samuel écrit un programme capable de s'améliorer en jouant aux dames. Depuis les progrès ne font que continuer et le machine learning est probablement le secteur de l'informatique le plus en expansion (reconnaissance faciale, conduite automatique, création de vaccins, aide à la prise de décision (data scientist),...).
Il existe dans ce domaine, différentes approches qu'il est intéressant de connaitre:
- Apprentissage supervisé: on a des exemples que l'on sait classer et qui sont déjà classées. L'ordinateur apprend avec les exemples et leur réponse, puis teste. Par exemple pour distinguer si l'on a une photo de chat ou de chien, l'ordinateur va analyser des centaines de photos dont il a la réponse.
- Apprentissage non supervisé: l'ordinateur a des exemples mais ne connait pas la réponse.
- Apprentissage par renforcememnt: l'algorithme apprend en observant ce qu'il essaye. Un système de récompense/punition lui permet d'améliorer ses choix. L'ordinateur joue au hasard au début et plus il apprend moins il joue au hasard et utilise ce qu'il a trouvé comme 'bonne méthode'. C'est avec ce genre de méthode que l'ordinateur peut apprendre à jouer à differents jeux. Le plus difficile est de choisir ce qui va être une récompense et ce qui sera une sanction. Un exemple des années 1990: les ascenseurs. Optimiser le programme de plusieurs ascenseurs pour une même tour.
- Apprentissage par transfert: utiliser des comptétences déjà apprises sur des nouvelles taches qui ont des points communs.
Description du problème
Notre problème est assez simple: on relève sur des objets de différentes classes des paramètres. On sait donc que pour tel objet de telle classe, on a tels paramètres. L'objectif est de pouvoir prévoir à quelle classe appartient un nouvel objet uniquement à l'aide de ses paramètres. il s'agit clairement d'un apprentissage supervisé.
Un peu d'histoire. Dans un rapport non publié de l'US Air Force School of Aviation Medicine publié en 1951, Fix et Hodges ont introduit une méthode non paramétrique de classification des schémas qui est depuis connue sous le nom de "K-nearest-neighbor classification" soit "k plus proches voisins" (Fix et Hodges, 1951). Plus tard en 1967, certaines des propriétés formelles des kppv ont été élaborées (Cover et Hart, 1967).
L'idée des k plus proches voisins est assez simple. Puisque l'on connait la classe et les paramètres de plusieurs objets on va dire que notre nouvel objet appartient à la classe dont il a le plus de voisins parmi les k plus proches
Par exemple, si je prends les 3-voisins d'un nouvel objet, je cherche les 3 voisins les plus proches de cet objet et je regarde à quelle classe ils appartiennent. Cela va déterminer à quelle classe on va attribuer le nouvel objet.
Voici un dessin. En bleu les chats, en rouge les chiens. On admet que x et y sont deux données mesurées sur les animaux qui permettent la discrimination (ces données sont bien sûr fictives, mais pour illustrer disons le poids et la taille). En bleu les chats, en rouge les chiens et en vert l'animal à prédire. On utilise la distance Euclidienne mais ce n'est pas une obligation.
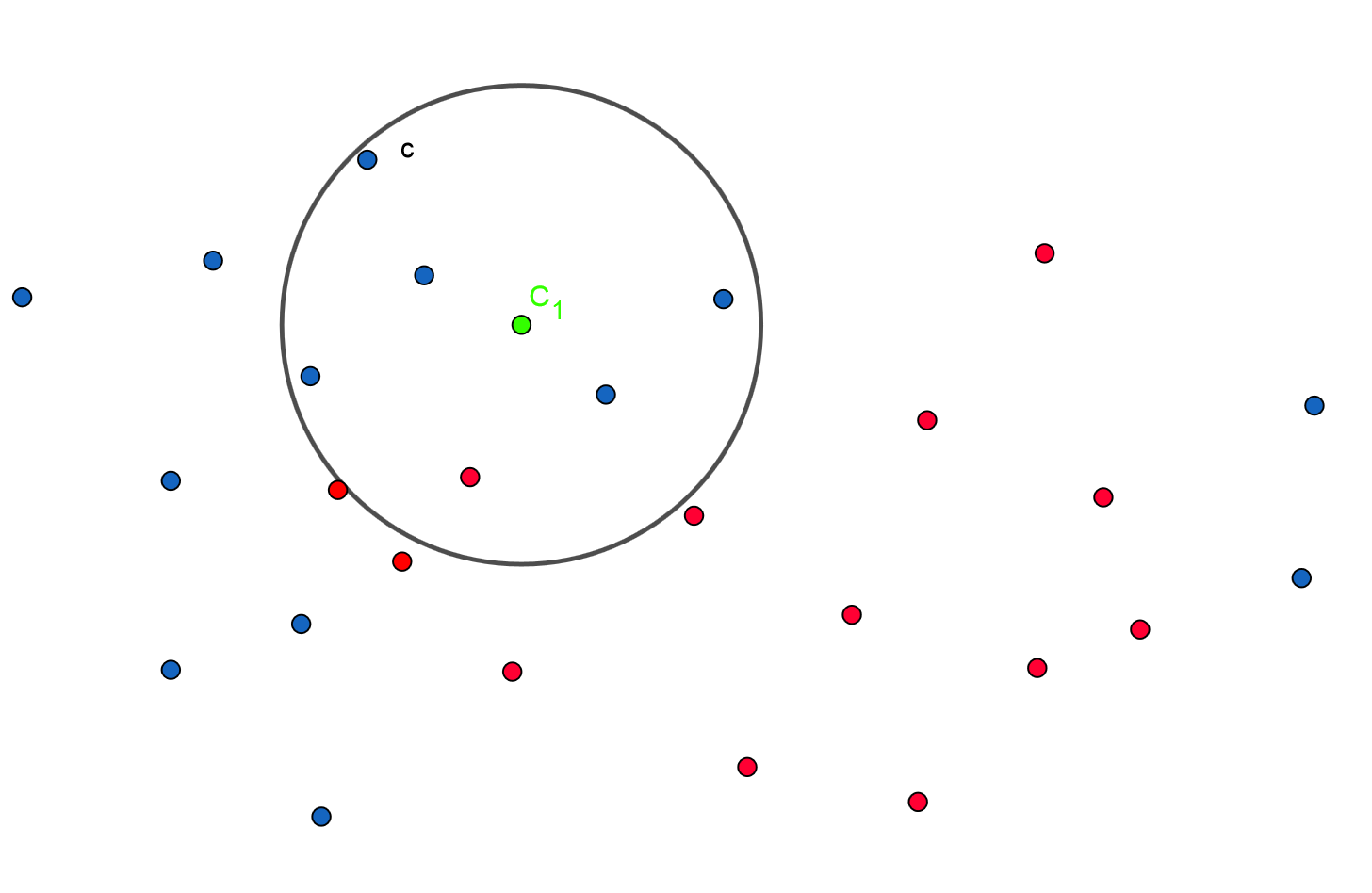
ci dessus, avec les k plus proches voisins et k=7 on prédit que le vert est un chat.
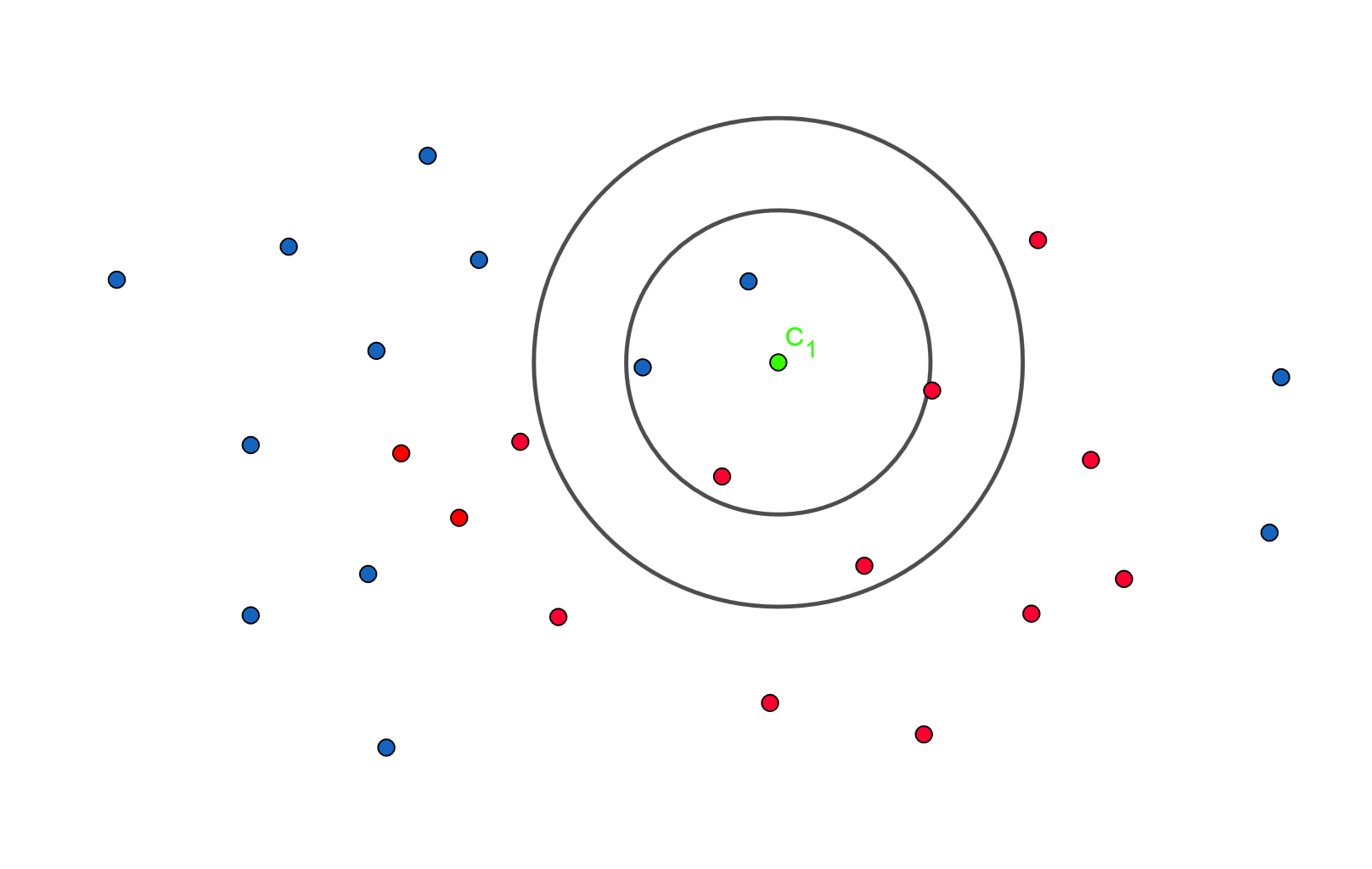
Ci dessus, la réponse change en fonction de k! Avec k=3 on repond un chat, avec k=5..un chien!
L'algorithme des k plus proches voisins
Tout réside dans le calcul de la distance entre le nouvel objet et les objets connus. Dans un repère orthogonal, avec donc 2 paramètres, c'est simple. Pour rester très général et donc multidimensionnel, nous allons imaginer qu'il existe une fonction distance(objet1,objet2).
Voici un algorithme simplifié qui suffit dans le cas de 2 couleurs comme dans le cours. Il est facilement adaptable à 3 couleurs mais à partir d'un nombre d'étiquettes (ici les couleurs) important mieux vaux regarder le second algorithme.
# fonction qui va retourner la liste des k kvoisins
# les plus proches d'un élément du plus proche au plus lointain.
➦ fonction k_plus_proches_voisins,
paramètres: liste des objets connus
nouvel objet
k: nombre de voisins
➦ Pour tous les objets connus
➦ calculer la distance entre objet connu et nouvel objet
➦ ajouter dans une liste 'liste_distance': cette distance et la couleur de l'objet
➦ ranger liste_distance dans l'ordre croissant des distances
➦ retourner la liste de 0 à k-1
## predire à quel groupe (étiquette) appartient nouvel objet
➦ fonction predire,
paramètres: liste des objets connus
nouvel objet
k: nombre de voisins
➦ kppv = k_plus_proches_voisins(liste objets connus,nouvel objet, k)
➦ couleur={"bleu":0,"rouge":0}
➦ pour tous les éléments de kppv
➦ si étiquette de l'élément= "bleu"
➦ ajouter 1 à couleur["bleu"]
➦ sinon
➦ ajouter 1 à couleur["rouge"]
➦ si couleur["bleu"]>couleur["rouge"]
➦ renvoyer "bleu"
➦ sinon
➦ renvoyer "rouge"
A noter que la première fonction peut être codée autrement. Si l'on veut k voisins. On prends les éléments un à un et au fur et à mesure on mémorise la plus grande distance. Dès que l'on a k valeurs dans la liste, on remplace l'élément max si on rencontre un élément plus près. Attention il faut alors retrouver le nouveau max. Cela peut paraître plus compliqué. Nous disposons de la commande sorted pour ranger nos listes et cette dernière est rapide et simple à mettre en oeuvre si le critère de tri est compris par python; du coup dans notre cas nous préférons l'algorithme proposé en premier. Mais si l'on veut ranger une liste selon un critère non numérique ou alphabétique, sorted sera inutilisable. Ranger dans l'ordre sera probablement plus couteux que la méthode que je viens jsute de décrire.
Voici un algorithme plus général:
# fonction qui va retourner la liste des k kvoisins
# les plus proches d'un élément du plus proche au plus lointain.
➦ fonction k_plus_proches_voisins,
paramètres: liste des objets connus
nouvel objet
k: nombre de voisins
➦ Pour tous les objets connus
➦ calculer la distance entre objet connu et nouvel objet
➦ ajouter dans une liste 'liste_distance': la distance et le type de l'objet(son étiquette)
➦ ranger liste_distance dans l'ordre croissant des distances
➦ retourner la liste de 0 à k-1
## predire à quel groupe (étiquette) appartient nouvel objet
➦ fonction predire,
paramètres: liste des objets connus
nouvel objet
k: nombre de voisins
➦ kppv = k_plus_proches_voisins(liste objets connus,nouvel objet, k)
➦ initialiser compteur_etiquette à [0] * nombre d'étiquettes différentes (liste donc de 0)
➦ pour tous les éléments de kppv
➦ pour i de 0 au nombre d'étiquettes-1
➦ si étiquette de l'élément égal à étiquette[i]
➦ ajouter 1 à compteur_etiquette[i]
➦ renvoyer (etiquette[index_maxi(compteur_etiquette)])
Un exemple/exercice en Python
Pour cet exemple nous allons prendre les notes de deux classes dans 4 matières. Réaliser ce programme.
Pour mesurer l'efficacité de la méthode, on supprime un élève au hasard et on essaie de déterminer la classe dans laquelle il est. On peut ainsi voir si l'on fait faux. En supprimant un a un tous les élèves, on calcule le nombre d'erreurs pour 1-voisin, 2-voisins etc et on peut ainsi choisir le k-optimal. Je laisse ceci en exercice.
Bien évidement cela ne donne des résultats concluant que si les classes (ou les enseignants) donnent des notes différentes (par exemple notes basses dans une discipline pour une classe et haute dans l'autre). J'ai testé sur 4 classes réelles (100 élèves) et des notes de brevet sur 4 matières (donc comme si c'était le même correcteur pour tous!). En pronostiquant au hasard on fait 84% d'erreurs, le meilleur k est 4 et avec les 4-voisins l'erreur est de 74%. J'ai ensuite construit un réseau de neurones (qui tourne 3 minutes max), avec 50000 passes et 3 ou 4 couches de neurones on arrive à 66% d'erreurs mais avec 250 couches de neurones on arrive à 15% ! Intéressant non. Je nuance toutefois, le taux d'erreur pour le réseau de neurone est calculé avec un modèle dont je n'ai pas retiré l'élève pronostiqué. Pour avoir un taux réel il faudrait supprimer les élèves un à un, chercher les paramètres (3 minutes au moins) et voir le pronostic et ceci pour les 100 élèves.... je vais attendre de changer de pc et j'actualiserais!
Exercices
-
Nous allons utiliser les dicitionnaires pour décrire nos objets qui seront de la forme:
{couleur:"bleu","x":100,"y":120}
Nous ferons une liste contenant des dictionnaires du type précédent. Cela constituera les objets donnés. Veillez à ce que les bleus ne soient pas trop mélangés avec les rouges.
La distance utilisée sera la distance Euclidienne dans un repère orthonormé.
Coder l'algorithme des plus proches voisins et faites des prédictions. Par exemeple: predire(liste_connus,3,{"x":55,"y":70})






